Cos'è un' ontologia?
Jim Hendler
A set of knowledge terms, including the
vocabulary, the semantic interconnections and
some simple rules of inference and logic for
some particular topic
Studer et al. (1998)
An ontology is a formal, explicit specification of a
shared conceptualisation.
A 'conceptualisation' refers to an abstract
model of some phenomenon in the world by having
identified the relevant concepts of that
phenomenon.
'Explicit' means that the type of concepts
used, and the constraints on their use are explicitly
defined. For example, in medical domains, the concepts
are diseases and symptoms, the relations between them
are causal and a constraint is that a disease cannot
cause itself.
'Formal' refers to the fact that the ontology
should be machine readable, which excludes natural
language.
'Shared' reflects the notion that an ontology
captures consensual knowledge, that is, it is not
private to some individual, but accepted by a group.
Perché puntare sul semantic web?
Le previsioni Gartner nel 2007
By 2017, we expect the vision of the Semantic Web
[…] to coalesce […] and the majority of
Web pages are decorated with some form of semantic
hypertext.
By 2012, 80% of public Web sites will use some level of
semantic hypertext to create SW documents […]
15% of public Web sites will use more extensive
Semantic Web-based ontologies to create semantic
databases
(nota: “semantic hypertext” si riferisce a
strumenti e tecnologie come RDFa, microformat
eventualmente con GRDDL, etc.)
Source: “Finding and Exploiting Value in
Semantic Web Technologies on the Web”, Gartner
Research Report, May 2007
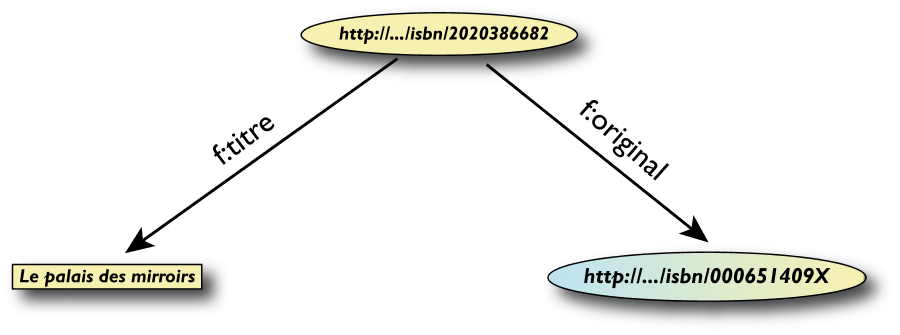
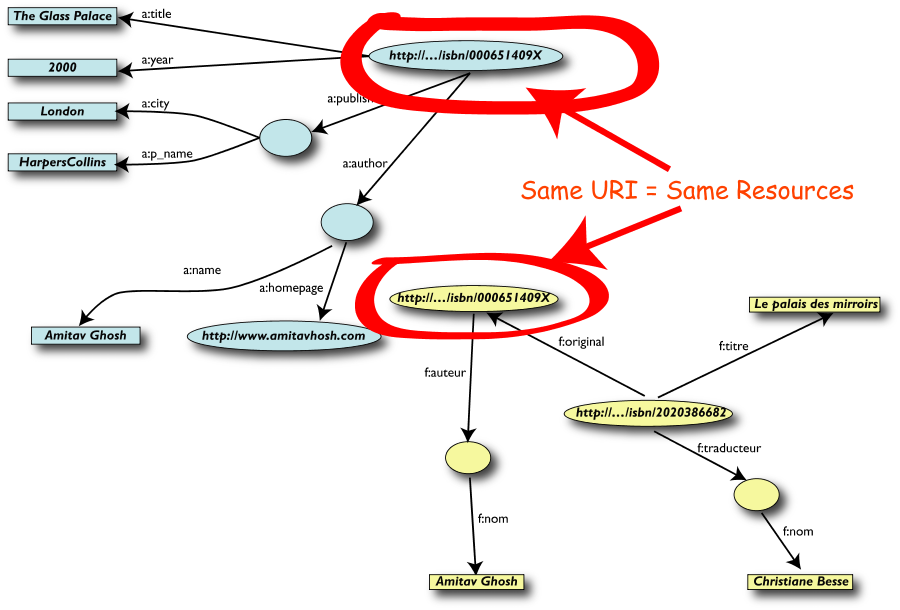
Un esempio semplice di RDF (in RDF/XML)
<rdf:Description rdf:about="http://…/isbn/2020386682">
<f:titre xml:lang="fr">Le palais des mirroirs</f:titre>
<f:original rdf:resource="http://…/isbn/000651409X"/>
</rdf:Description>
(Nota: per semplificare gli URI sono stati usati i
namespace)



{kind=link}
{kind=link}